The Disconnect Between AI Development and User Needs
A growing chorus of AI users is questioning whether the industry has lost sight of what made large language models valuable in the first place. As companies race to build autonomous agents and coding assistants, a Reddit discussion gaining significant traction reveals deep frustration with the current trajectory of AI development.
"The thing that brought me to LLMs 3 years ago, was the ability to obtain custom-fit knowledge based on my context, avoiding the pathetic signal-to-noise ratio that the search engines bring," writes one user in a post that resonated with the community, garnering 109 upvotes and 89 comments. The sentiment captures a broader discontent: while AI labs focus on making models "as agentic as possible," users worry that "with the limited number of params, focusing on agentic task will surely degrade model's performance on other tasks."
Performance Claims Meet Reality
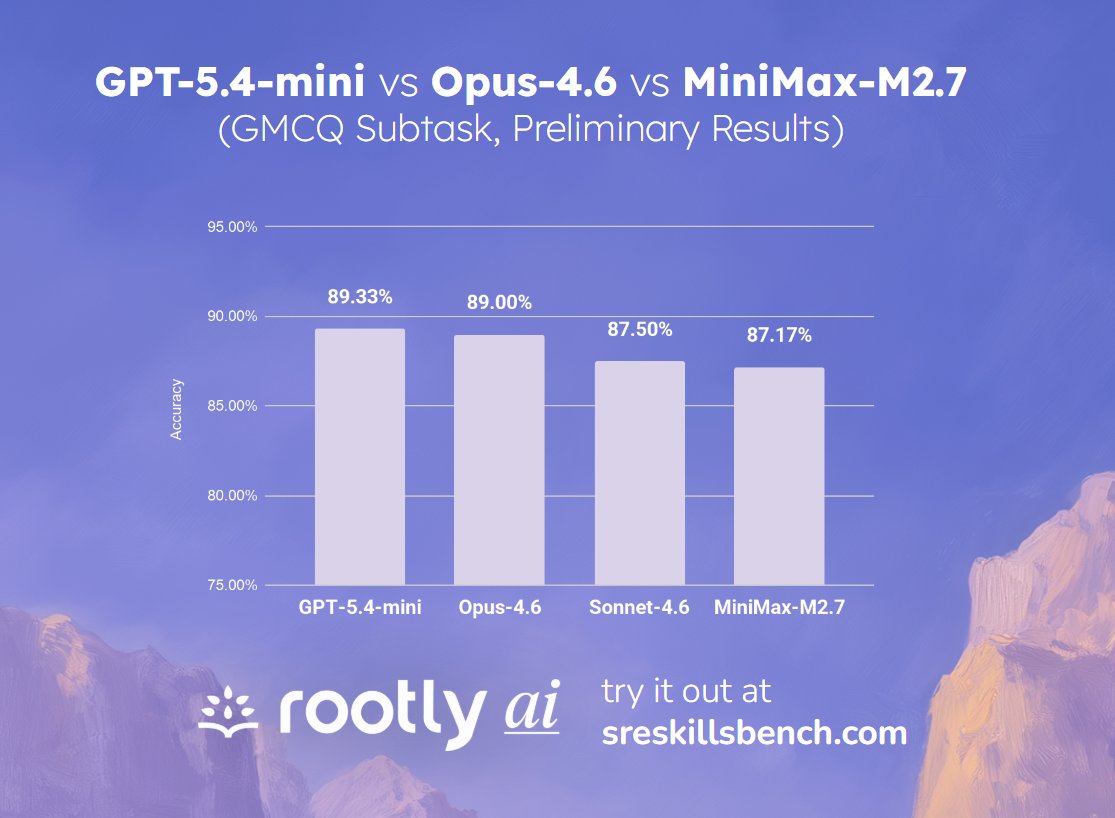
The tension between marketing promises and real-world reliability became stark this week. While Laurence Liang reported on Twitter that "GPT-5.4-mini is comparable to Opus-4.6 for SRE scenarios," suggesting competitive parity between models in specialized technical domains, Claude's status page told a different story. The platform experienced "elevated errors on Claude Opus 4.6," forcing users to confront the gap between benchmark performance and operational reliability.
This juxtaposition highlights a fundamental challenge: even as models claim parity or superiority in specific use cases, basic service reliability remains elusive. The incident, which triggered 31 comments on Reddit, underscores how performance comparisons mean little when users can't reliably access the models.
The Hardware Reality Check
Meanwhile, in the trenches of practical AI deployment, developers are grappling with the physical constraints of running increasingly large models. A technical discussion about running Qwen3.5-397B reveals the stark realities of local deployment. Users are attempting to run this massive 397-billion parameter model on hybrid GPU and system RAM setups, with Unsloth claiming "25+ tok/s on a single 24GB GPU + 256GB system RAM."
However, as one developer notes, "DDR5 on a mainstream platform is roughly 10x slower than GPU VRAM bandwidth," meaning performance varies wildly depending on hardware configuration. This technical reality check serves as a metaphor for the broader AI landscape: impressive specifications often collide with practical limitations.
What Users Actually Want
The community's frustration centers on a simple request: "Are there any LLM labs focusing on training a simple stupid model that has as much knowledge as possible? Basically an offline omniscient wikipedia alternative?" This plea for knowledge-focused models over agent capabilities reveals a fundamental misalignment between what AI companies are building and what many users actually need.
As we've previously covered, the industry is splitting between maximum integration approaches and minimal assistance tools. But this latest user revolt suggests a third path is desperately needed: models that excel at their original promise of providing reliable, contextual knowledge without the complexity of autonomous agents or the brittleness of cutting-edge features.
The trajectory is clear: user frustration is escalating as the gap widens between AI development priorities and actual user needs. Until the industry addresses this fundamental disconnect, we may see more users questioning whether the pursuit of artificial general intelligence has come at the cost of artificial reliable intelligence.